Hadoop YARN cgroup stability issues
- Technology

About Control Groups
Control Groups (cgroups) is a Linux mechanism to isolate tasks and control resource access and usage. Nowadays it is very widely used, from systemd to Docker. YARN is also able to leverage cgroups to take the CPU into account for scheduling, and control the CPU usage of containers (as opposed to controlling the memory only).
The issue
As usage of our cluster grew, we started to have stability problems with worker nodes crashing. As we had setup our nodes to auto-reboot on lockups using the Linux watchdog, at first the problem was barely noticeable: a node would reboot from time to time, but the Hadoop ecosystem is pretty resilient with multiple replicas of data, or automatic rerun of failed tasks.
Most likely due to changes in usage patterns, the odd node reboot suddenly turned into a much more serious problem. At the worse point we had up to 20% of all nodes die each day, often multiple at the same time.
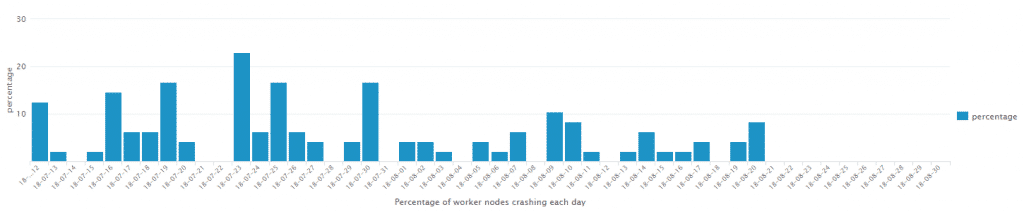
At that stage it creates real problems: HDFS blocks can be temporarily missing, YARN tasks (and in particular Application Masters) can fail too many times leading to the overall jobs failing, or a node involved in Spark shuffle becomes unavailable, which makes every executor which expects data from that node to fail, and in turn it can cause the Spark jobs to fail.
Example of failure:
ERROR [org.apache.spark.sql.ex.datasources.FileFormat]- Aborting job null. org.apach.spark.SparkException:
Job aborted due to stage failure: Task 28539 in stage 2 failed 4 times, most recent failure: Lost task 28539.3 in 256.0 (TID 259831, slave35.dom, executor 946):org.apache..hdfs.BlockMissingExcept: Could not obtain block: BP-1300701248-123.123.123.4-14:blk_1164305020_
Troubleshooting
We seemed to see a pattern around a network driver in the kernel crash stack dumps, and decided to try a different one than the one built-in the Linux kernel. As we did throughout this investigation, we first rolled it out to a small subset of nodes, and waited to observe whether it appears to help or not. This can take time – you need enough failures of nodes you haven’t changed, with hopefully no failure (or at least a different failure) of the nodes you changed, to gain confidence that the change helped. In our case, we would typically need a few days to find out. On multiple occasions, after a change, everything looked fine for a week or so… and then the crashes would start again – surely we were unlucky with usage patterns muddying the water? The driver helped, and this crash stack dump “signature” seemed to go away… but nodes were still crashing, now with a fairly obscure stack dump, that seemed to be around the Linux kernel scheduler:
[626082.196394] NMI watchdog: Watchdog detected hard LOCKUP on cpu 8 [...] [626082.196495] Call Trace: [626082.196499] [<ffffffff816a904d>] __schedule+0x39d/0x8b0 [626082.196501] [<ffffffff816aa4a9>] schedule_preempt_disabled+ [626082.196504] [<ffffffff810e7c1a>] cpu_startup_entry+0x18a/0x1c0 [626082.196507] [<ffffffff81051af6>] start_secondary+0x1b6/0x230 [626082.196524] Kernel panic - not syncing: Hard LOCKUP [...] [626082.196648] Call Trace: [626082.196656] <NMI> [<ffffffff816a3e51>] dump_stack+0x19/0x1b [626082.196676] [<ffffffff8169dd14>] panic+0xe8/0x20d [626082.196690] [<ffffffff8108772f>] nmi_panic+0x3f/0x40 [626082.196704] [<ffffffff8112fa85>] watchdog_overflow_callback+ [...] [626082.197514] [<ffffffff810c89d1>] ? tg_unthrottle_up+0x11/0x50 [626082.197809] <<EOE>> <IRQ> [<ffffffff810c0bdb>] ? walk_tg_tree_from+0x7b/0x110 [626082.198115] [<ffffffff810ba1a0>] ? __smp_mb__after_atomic+0x10/ [626082.198422] [<ffffffff810d0987>] unthrottle_cfs_rq+0xb7/0x170 [626082.198724] [<ffffffff810d0c0a>] distribute_cfs_runtime+0x10a/ [626082.199034] [<ffffffff810d0db7>] sched_cfs_period_timer+0xb7/ [...]
We thought that it may be a red-herring (the scheduler is one of the most used and thus tested code in the kernel) so we extended our investigation to other drivers, and a few settings, one experimental group at a time… but still, crashes would carry on.
At some point, we thought we would try to limit the resource usage of the YARN containers, hoping that by reducing the stress on the worker nodes, we would limit the issue. One setting we tried changing was yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage. Setting this to true makes YARN enforce a strict limit on the CPU usage of each container. In our case, it turns out that this had a significant negative impact on our jobs stability and performance, without improving the node stability. The search continues…
Something odd
Limiting resource usage further with cgroups was not the way, but we noticed something odd with the cgroups. We had hundreds of cgroups created by YARN on each node, or even thousands in some cases.
We expected more or less one cgroup per running executor, but the number of cgroups was order of magnitudes higher than this, and in fact way higher than we could reasonably expect on a node. On closer look, the vast majority had no task in them, and appeared to have been created a long time ago: YARN was leaking cgroups, i.e. not always removing them properly after the end of some executors. Looking closer at YARN logs, we could see it warn about those:
2018-08-14 06:02:24,014 WARN util.CgroupsLCEResourcesHandler (CgroupsLCEResourcesHandler.java:deleteCgroup(351)) - Unable to delete cgroup at: /sys/fs/cgroup/cpu,cpuacct/yarn/container_e324_1533827879776_10644_01_000126, tried to delete for 1000ms
That seemed odd, but how could it be relevant with our worker node stability?
Eureka
Luckily we had a Linux support subscription for affected nodes. While there have been periods where we haven’t needed much support from the vendor (we would still benefit from all their hard work of packaging, patching, etc), it is one of these cases where having access to kernel experts was a definite plus. We raised a ticket with them about our OS stability issues, and ended up discussing the cgroups. On closer look, they narrowed it down to a portion of the Linux scheduler code that could take too long too run when the node is particularly busy (our nodes are!) combined with too many cgroups, which in turn ends up with a hard lockup and the system effectively freezing. Then the kernel watchdog kicks in, and the server reboots.
This also explained why on multiple occasions, after trying a change (and often rebooting the worker nodes in question) they appeared stable for a few days (raising our hopes) before going wrong again: it was the time it took for the cgroups to accumulate.
So we started by putting in place a simple cron job to delete all cgroups (which essentially looks at /sys/fs/cgroup/cpuacct/yarn/cont* and removes all empty cgroups who are more than two-day old) and the crashes went away!
The Linux provider also carried on and reproduced the issue without YARN. They found a patch from a newer version of Linux that does help with this issue, and they are backporting it.
We also have support with a Hadoop vendor, and raised YARN failing to delete some cgroups with them. When an executor is terminated, YARN sends it a TERM signal and tries to remove the cgroup for up to 1 second (as defined by yarn.nodemanager.linux-container-executor.cgroups.delete-timeout-ms). However Linux will only let it remove the cgroup if it has no task, i.e. the executor process has exited. In cases it can take more than one second for the executor to exit, in which case YARN gives up removing the cgroup and leaves it there, so we end up with cgroups accumulating over time. It seems to us that the logic of YARN should be improved there: the typical behaviour is to send a TERM signal, give the process a reasonable amount of time to stop cleanly, and if it fails to do so finish it off with a hard KILL signal. That is what systemd does by default for instance. Shouldn’t YARN do the same, and only give up removing the cgroup after it has emitted the KILL signal to the executor?
To reduce the risk as much as possible, we also increased this timeout to 5 seconds. It seems to prevent any cgroup from accumulating on our cluster, however we are conscious that there is no guarantee all executors will stop nicely in that amount of time forever, so we left the cron job as an extra safety.
Putting it all together
So the main problem turned out to be a combination of an issue with YARN leaking cgroups, and the Linux kernel bug causing hard lockups when there are too many cgroups on a busy node.
The short term fix was to limit the risk of YARN leaking cgroups, combined with a cgroup clean-up job should any go through the net.
The longer term fixes would be a more robust clean-up of cgroups in YARN, as well as a more robust Linux kernel code to keep stable despite large number of cgroups. On the kernel side, a patch improving the behaviour is already available (“sched/fair: Fix bandwidth timer clock drift condition” https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) and it is being backported to the Linux provider version of the kernel.
Learnings
Bugs in third party code are out of our control, but we can still reflect on ways we could have solved this issue quicker.
With hindsight, the best way we could have done so would be to have spotted and started working on the problem before it got out of control. So basically keep an eye on small problems that could escalate. Best to fix them before it is too late.
However this is not always easy to prioritize what to investigate the most – for instance is a node crash due to a wider problem that may affect all nodes, or the odd hardware issue on a single box? Spending large amount of time on all small anomalies may not be what brings the most value to your users (your time might be better spent on new features or improving on issues or inefficiencies you already know about), but it is worth capturing metrics and logs that will help see the tree from the wood, and then save precious time investigating the issue when it becomes clear it needs to be followed up.
Thibault Godouet – Big Data Platform Manager, Technology