This article is one of a series of paper reviews from our researchers and machine learning engineers – view more
Machine Learning (ML) is a fast evolving discipline, which means conference attendance and hearing about the very latest research is key to the ongoing development and success of our quantitative researchers and ML engineers.
As part of their attendance at ICML 2023 in Hawaii, we asked our quants and machine learning practitioners to write about some of the papers and research that they found most interesting.
Here, Casey H, Machine Learning Engineer at G-Research, discusses two papers.
DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D. Manning, Chelsea Finn
With content from large language models (LLM) flooding the internet after the release of ChatGPT late last year, there has been increased research into how to detect machine generated text.
Without a way to detect fake content, one concern is that new LLMs will have difficulty distinguishing valid training data from data that was generated by a model.
A variety of solutions to this problem have been proposed, many of which create another smaller language model designed to classify text as human or model generated. DetectGPT, on the other hand, takes a different approach.
The authors based their classifier on the simple empirical observation that language models tend to generate text that the model thinks has high probability. Specifically, the generated text will tend to lie close to a local maximum of the “log likelihood” surface.
Human generated text, however, tends to exist elsewhere on this surface. This is depicted in the figure from the paper reproduced below
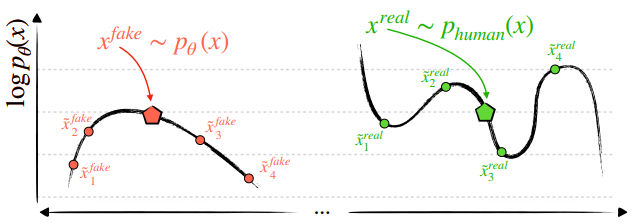
The black curve denotes the log probability of the model’s output. Model generated text will tend to look like the picture on the left (near a maximum) while human text will tend to look like the picture on the right (not necessarily near a maximum)
With this observation, the authors propose a detector based on making small edits to some given text (such that the meaning is unaltered) and allowing the model to evaluate the log probability of each.
If the text was generated by the LLM in question, the model assigns a lower log probability to the rephrasings than to the original text. For human generated text, rephrasings may achieve higher or lower log probability than the original text, according to the model. If enough rephrasings have lower log probability than the source text, then it is determined to have been generated by the model. The entire process is summed up in the first figure from the paper.
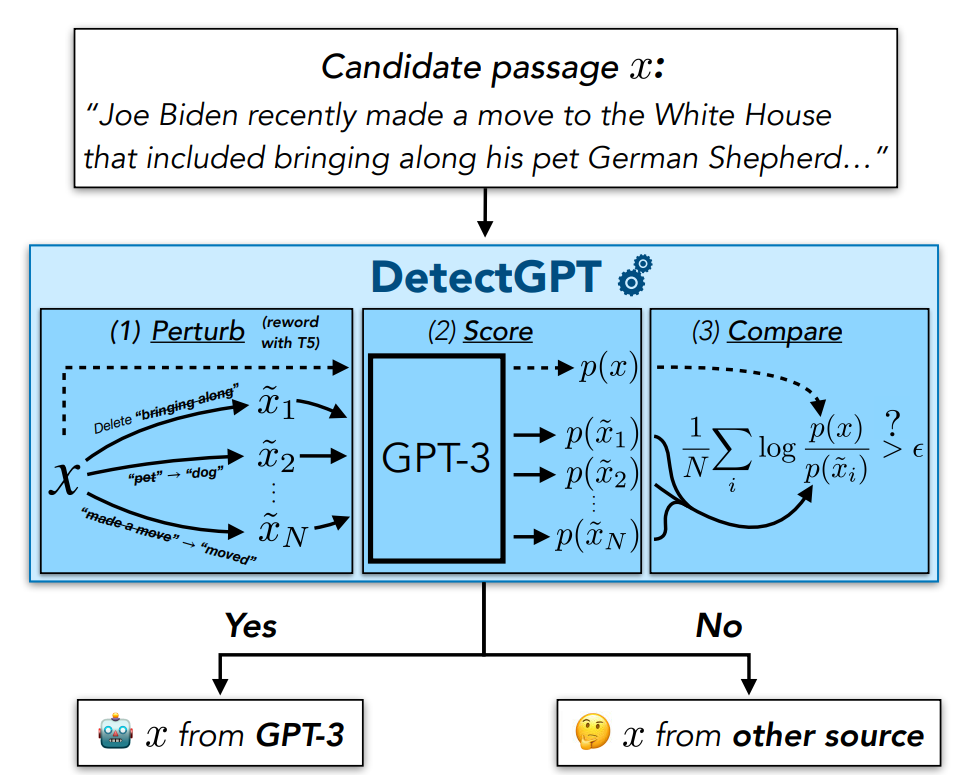
Several rewordings of the original source text are generated. The model is used to score the original text along with the rewordings. If the average difference between the rewordings and the original is high, the text is classified as having come from the model.
The main advantages of this approach are:
- requires no training of a new model
- works on any LLM with no knowledge of architecture or parameters
However, there are several drawbacks to DetectGPT as well. Namely:
- needs a specific LLM to detect
- requires evaluation of the model’s log likelihood (ChatGPT, for example, does not provide this)
- inferences the source model once for each perturbation of the sample text (there may be 100+ perturbations)
Despite its limitations, DetectGPT is a particularly simple and elegant solution to an increasingly large problem.
Resurrecting Recurrent Neural Networks for Long Sequences
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, Soham De
Transformer models have been the backbone of nearly all of the major AI advancements since its publication in 2017. However, there has been renewed interest in a different type of model for sequences referred to as state space models (SSMs).
SSMs have a long history in controls but have not gotten much uptake in the machine learning community. SSMs look a lot like recurrent neural networks, except they are completely linear.
One of the difficulties the authors of this paper saw with wider adoption and usage of SSMs was the mathematical complexity of describing these models and the intuition behind why they worked.
While transformers are conceptually simple, SSMs are derived by bringing together mathematics from a variety of fields including signal processing, control theory, and measure theory.
This paper performs an ablation study to try and figure out which components of SSMs are really necessary for getting good models. The authors were able to breakdown the complex mathematics of SSMs and by doing so, discovered much simpler maths underlying SSMs while still achieving good model performance.
This paper was noteworthy for its ability to attribute each feature of the SSM model to its affect on model performance and provide a new way to understand this important class of models.
Git-Theta: A Git Extension for Collaborative Development of Machine Learning Models
Nikhil Kandpal, Brian Lester, Mohammed Muqeeth, Anisha Mascarenhas, Monty Evans, Vishal Baskaran, Tenghao Huang, Haokun Liu, Colin Raffel
Git theta is a new plugin for the popular version control tool git.
The authors’ hypothesis is that model creation is not done collaboratively simply because we lack the suite of tools required to do it effectively. They draw parallels to the software days of old which lacked a lot of the best practices and methodologies that have been developed in the decades that followed.
The creators of git theta argue that machine learning and data science occupy a similar space that software did all those years ago. They suggest more tooling built for purpose will enable machine learning research and engineering to graduate to the level of software engineering.
The paper introduces the design of a plugin that enables authors of machine learning models to collaborate in much the same way that authors of software do.
git was built for handling files of human readable text (namely, source code for the Linux kernel). Machine learning models on the other hand tend to consist of billions of parameters organised into various arrays of numbers.
In its standard usage, git treats files containing model parameters as one big monolithic blob of data. Changing even a single byte will cause git to store an entire new copy of the file. Worse still, things like highlighting differences in a file before and after a change, resolving conflicts when two people have made changes to the same part of a file, are all lost when putting these files under git version control.
To bring back the useful functionality you get using git with text files, the authors of the extension make use of the structure inherent in almost all machine learning models. Instead of treating the file as one blob, they introduce the notion of “parameter groups”. This way, each array of numbers in the model (of which there may be thousands) is stored separately.
This enables a researcher to adjust the parameters in the last layer of a neural network, for example, and allow other collaborators to easily view their change. It also allows collaborators to make their own changes to other layers of the network without risk of a change conflict. This also avoids the problem of single byte changes to a 100GiB model creating another 100GiB copy. Instead, only a single parameter group needs to be copied.
Although not a traditional machine learning paper expected at ICML, this paper stood out as a clever solution to a problem faced by nearly all industry practitioners of machine learning.