Thinking outside the box with Ansible
- Software engineering
Mark Wadham, one of our engineers, discusses how he manages Ansible vars.
I’ve never liked the native Ansible vars system much, it always felt a bit limited. What most companies end up doing is using group vars for most of their config, but group vars are all loaded together indeterminately so it doesn’t really give you a good way to have a hierarchical structure where things at lower levels can override settings at higher levels.
The lack of this inheritance pattern tends to lead to hacky solutions that try to implement variable overriding, but lead to messy code. This is exactly the situation that the LAMPE Ansible codebase was in when I joined G-Research.
What I see in most companies I’ve worked for is that there is a natural hierarchy of concepts within their environment. If they’re on AWS it might be:
Region -> Environment (prod/dev etc) -> Product -> Service -> Customer
G-Research’s natural environment hierarchy looks a bit different to this as we’re not so cloud native, but it doesn’t really matter what the hierarchy points are – the point is that there is some kind of hierarchy. Someone working on configuration management would naturally want to be able to set vars at (using the example above) the region level and have them trickle down to the other levels, but still be able to override them at those lower levels if they want to.
This isn’t really viable using the group vars model as all of the vars files are loaded indeterminately together, at least by default.
However there is a way I’ve found to implement an arbitrary vars hierarchy in Ansible and I’ve used this at a few companies I’ve worked at in the past with great success.
Start by defining your hierarchy and the points at which you’d like to set vars, and then simply create a directory structure with vars files that reflects this. I like to keep things simple and have all the vars filed called vars.yml and all the files containing vault secrets called vault.yml.
So for example it might look something like this:
vars/region/eu-west-1/vars.yml vars/region/eu-west-1/vault.yml vars/env/dev/vars.yml vars/env/dev/vault.yml vars/product/product1/vars.yml vars/product/product1/vault.yml vars/service/service1/vars.yml vars/service/service1/vault.yml vars/customer/customer1/vars.yml vars/customer/customer1/vault.yml
You could have the directory structure be hierarchical too if you want, it doesn’t really matter. I like to keep it semi-flat like the above just because I’ve found in the past that the hierarchy isn’t always fixed in stone and keeping things flat makes it easier to tweak the inheritance order or create exceptions to it.
So now we have something like our ideal vars structure on disk, and a conceptual hierarchy of concepts in mind. To make this into reality we need to:
- Associate the appropriate pieces of metadata to the host in some way. In the LAMPE team we do this with host group tags in a static inventory, but in the cloud this might be done with EC2 tags or whatever other mechanism you like. If you’re pre-baking images you could pass these in at runtime via environment variables.
- Write a loadvars role. This role will be included at the start of every playbook and will deal with inferring the variable scope and loading the appropriate vars for you.
Our loadvars role is very simple:
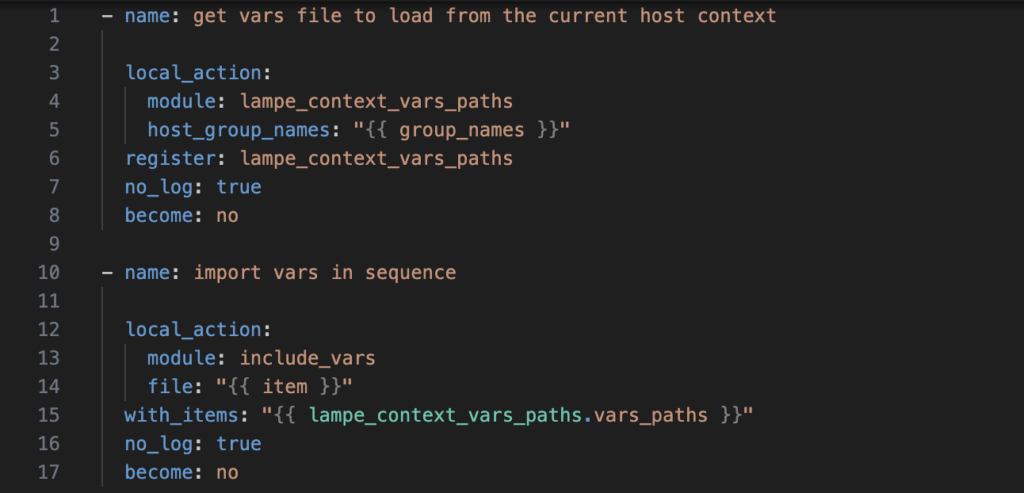
- Write the helper library for the loadvars role that infers the scope for the host, eg its region, environment, product, service, customer etc and then determines which vars files should be loaded and in what order. It then simply needs to pass these back to the loadvars role in the correct order and they will be loaded in sequence and respect the hierarchy.
Vars that are at lower points will override vars set at higher points. As an additional bonus you can also set hash_behaviour to “merge” so that the underlying python will merge dictionaries rather than replacing them. This makes it possible to even override specific keys in a dictionary that was already defined at a higher level.
So lets say your region.yml contains something like:
ec2_instance_type: region: eu-west-1 size: t2.micro count: 1 security_groups: - group1 - group2
Now lets say you have one product in your environment that doesn’t run correctly with a t2.micro and needs a bigger instance type. You can now simple override it in the vars file for the product with:
es2_instance_type: size: t2.large
The two dictionaries will be merged together and because the product-level vars are loaded after the region-level vars they will take precedence and override vars at the region level.
I think this is a much more powerful way to manage Ansible vars than the native system provides for.
Mark Wadham – Engineer