Written by Enrico Minack, Open Source Software Contributor
The Spark UI is key when it comes to inspecting what a Spark application is actually doing, from exploring performance bottlenecks to looking for correctness issues. The UI allows for navigating Spark jobs, stages and tasks, performance metrics and executor health.
Using job descriptions increases the readability of the Spark UI as it provides context to queries, jobs and stages, which is especially helpful for large Spark jobs.
This article discusses how job descriptions improve readability of the Spark UI, and the caveats that exist with multi-threaded Spark applications.
The Spark UI
The Spark UI is the primary place to find insights into what a Spark application is doing, to investigate performance issues, or to find bugs. First, we start with an example dataset to later have a look at what the Spark UI can tell us:
val data = spark.range(10).select($"id", ($"id" * 2).as("even"), ($"id" * 2 + 1).as("odd"))
data.show(3)
+---+----+---+ | id|even|odd| +---+----+---+ | 0| 0| 1| | 1| 2| 3| | 2| 4| 5| +---+----+---+ only showing top 3 rows
Let’s also define a method that writes one column (and the id column) into a file:
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions.col
def writeColumn(df: DataFrame, column: String, filename: String): Unit = {
df.select($"id", col(column)).coalesce(1).write.option("header", true).csv(filename)
}
Now we write columns even and odd. Using that handy method, we pipe the dataset into two new, distinct files:
Seq("even", "odd").foreach(column => writeColumn(data, column, s"$column.csv"))
Our Spark application has created two CSV files, even.csv and odd.csv:
id,even 0,0 1,2 2,4 …,…
id,odd 0,1 1,3 2,5 …,…
The Spark UI shows queries, jobs and stages involved in writing the CSV files. From that, we cannot see which query, job or stage is related to file even.csv or odd.csv. They are all called csv at JobDescriptions.scala:43, which is not very helpful.
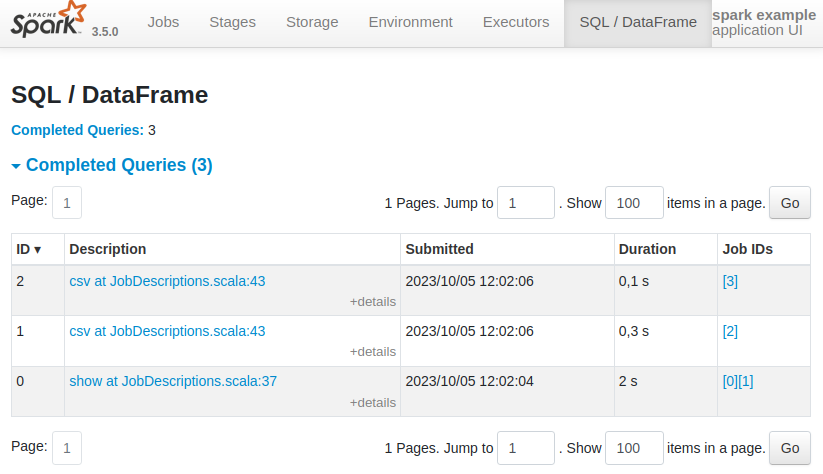
Firstly, one needs to have the source code at hand to translate csv at JobDescriptions.scala:43 into some meaningful context. Secondly, we use the generic method write that calls action Dataset.write.csv() on our dataset, so all queries refer to the same line of source code that calls that action. As a consequence, we cannot tell from the UI which query is writing even.csv, and which is writing odd.csv.
This is where Spark thankfully provides job descriptions.
Using job descriptions
A job description adds the missing meaningful context to Spark queries, jobs and stages. Any text message set via SparkContext.setJobDescription – before calling an action – will be used to decorate the respective query, job and stage in the Spark UI:
def writeColumn(df: DataFrame, column: String, filename: String): Unit = {
df.sparkSession.sparkContext.setJobDescription(s"Writing file $filename")
df.select($"id", col(column)).coalesce(1).write.option("header", true).csv(filename)
df.sparkSession.sparkContext.setJobDescription("")
}
The Spark UI now conveniently tells us which query refers to writing which file:
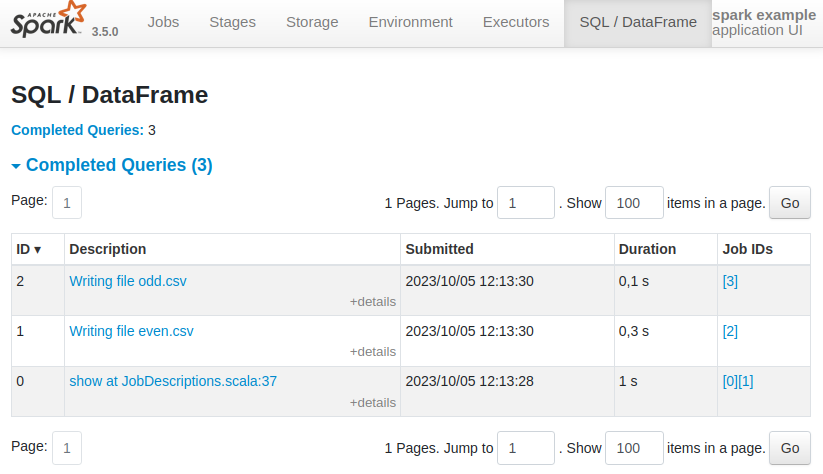
Note: The description has to be unset after calling the action so that the description does not leak to other actions called later (for example, outside this writeColumn method).
Easier job descriptions with spark-extension
Setting, and automatically resetting, job descriptions can be nicely done via withJobDescription, which is provided by the spark-extension package.
Instead of:
df.sparkSession.sparkContext.setJobDescription(s"Writing file $filename")
df.select($"id", col(column)).coalesce(1).write.option("header", true).csv(filename)
df.sparkSession.sparkContext.setJobDescription("")
we can write:
withJobDescription(s"Writing file $filename") {
df.select($"id", col(column)).coalesce(1).write.option("header", true).csv(filename)
}(df.sparkSession)
In some situations, it is useful to extend the current job description (“Splitting data by columns” in the below example) with more context (s”writing file $filename”) and restore it afterwards.
The spark-extension package provides the appendJobDescription method to do this easily:
def writeColumn(df: DataFrame, column: String, filename: String): Unit = {
appendJobDescription(s"writing file $filename") {
df.select($"id", col(column)).coalesce(1).write.option("header", true).csv(filename)
}(df.sparkSession)
}
withJobDescription("Splitting data by columns") {
Seq("even", "odd").foreach(column => writeColumn(data, column, s"$column.csv"))
}(spark)
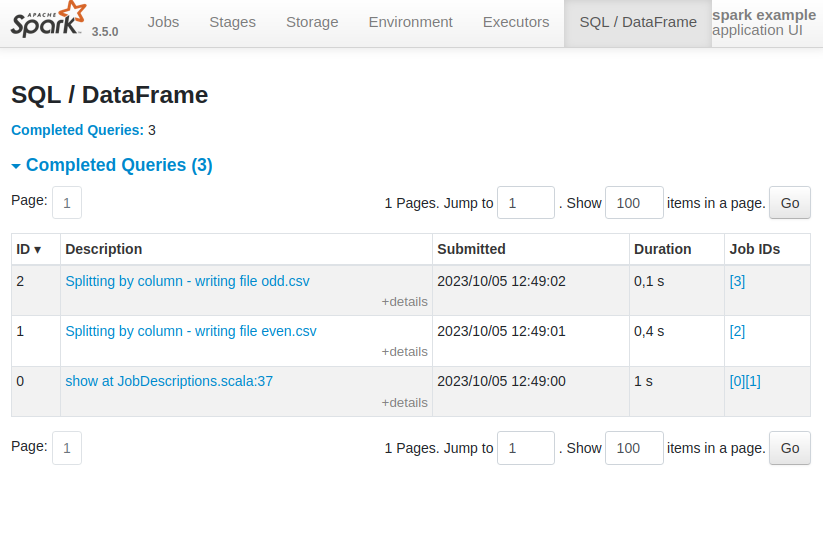
The Spark UI shows the job descriptions constructed by withJobDescription and appendJobDescription:
Multi-threaded Spark apps
Special care has to be taken when using job descriptions in conjunction with multi-threaded Spark applications. Let’s make the running example multi-threaded:
import scala.collection.parallel.CollectionConverters.seqIsParallelizable
// turn our sequence of column names into a parallel collection
val columns = Seq("even", "odd").par
withJobDescription("Sorted by id ASC") {
// now, .foreach() is executed in parallel
columns.foreach(column => writeColumn(data.sort($"id".asc), column, s"$column.asc.csv"))
}(spark)
withJobDescription("Sorted by id DESC") {
columns.foreach(column => writeColumn(data.sort($"id".desc), column, s"$column.desc.csv"))
}(spark)
Surprisingly, the description of the second batch of queries (with ID 3 and 4) has the same left part of the job description as the first batch (Sorted by id ASC, rather than the expected Sorted by id DESC). The right part of the job descriptions is correct (writing file odd.desc.csv and writing file odd.asc.csv).
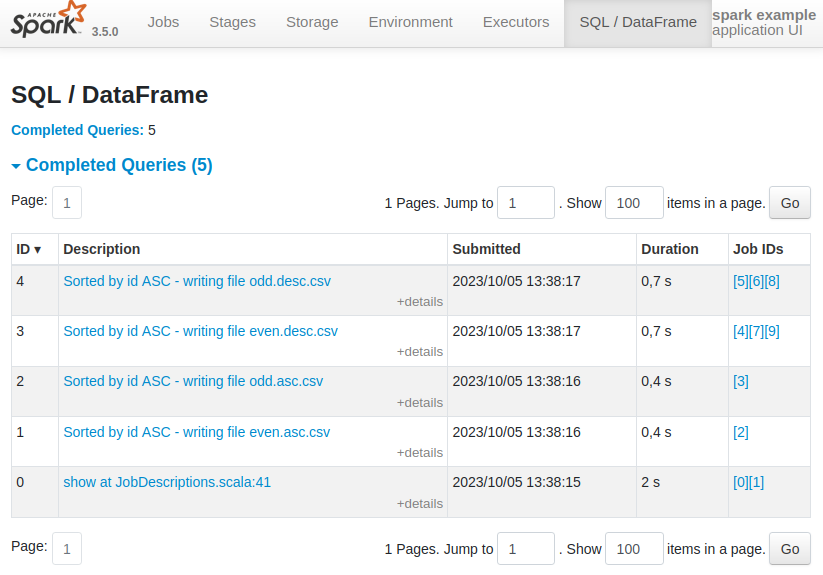
To understand what is going on here, we need to look at how the job description set via SparkContext.setJobDescription propagates to any action called on a dataframe.
A fundamental property of Spark is that only a single Spark context exists across a Spark application and all its threads[1]. Having the context exist in multiple threads would mean that setting the job description in one thread would set it for all threads. Actions called on any thread would use the description set by an arbitrary thread. Such a race condition would lead to non-deterministic assignment of descriptions and an awful mess in the Spark UI.
To avoid this, the job description is a property of the current thread only. Now, setting a job description in one thread does not change it for other threads, though they use the same Spark context instance. This is exactly how you would expect job descriptions to work.
Threads that are spawned from an original thread copy the local properties of the original thread. This explains why the first batch of queries has the right job description (Sorted by id ASC – …), because the first call to columns.foreach spawns new threads that use the job description and call the actions. The second call to columns.foreach reuses those threads, so consequently, the second call withJobDescription(“Sorted by id DESC”) does not modify the job descriptions for the existing threads used by columns.
This situation can be solved by enforcing columns to use a new pool (new ForkJoinPool()) of threads before we call into .foreach again:
import java.util.concurrent.ForkJoinPool
import scala.collection.parallel.ForkJoinTaskSupport
// turn our sequence of column names into a parallel collection
val columns = Seq("even", "odd").par
withJobDescription("Sorted by id ASC") {
// now, .foreach() is executed in parallel
columns.foreach(column => writeColumn(data.sort($"id".asc), column, s"$column.asc.csv"))
}(spark)
withJobDescription("Sorted by id DESC") {
// make sure the parallel collection uses a new pool of threads to execute the actions
// only this propagates the job description to the thread executing the action
columns.tasksupport = new ForkJoinTaskSupport(new ForkJoinPool())
columns.foreach(column => writeColumn(data.sort($"id".desc), column, s"$column.desc.csv"))
}(spark)
The Spark UI presents the expected job descriptions:
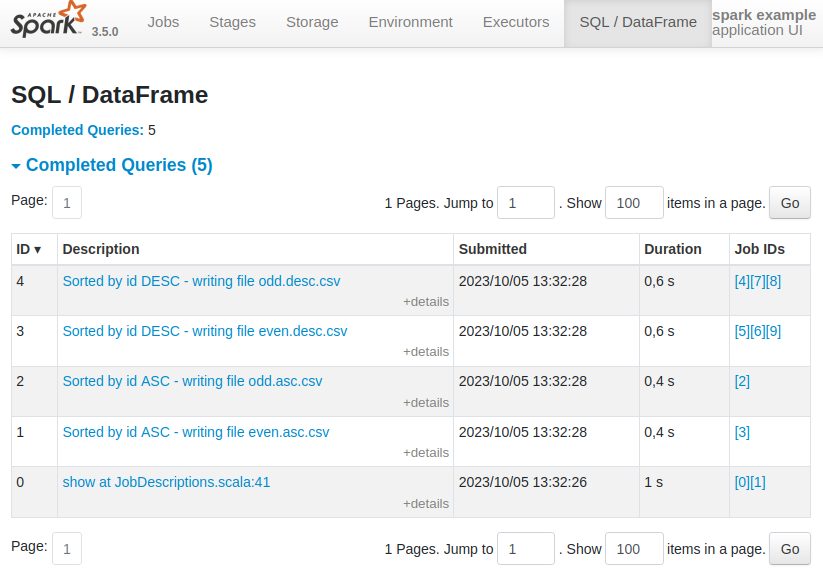
Creating a new thread pool ensures columns.foreach spawns new threads. This should also be done the first time calling columns.foreach to ensure it does not reuse some other pre-existing pool of threads.
To summarize the findings:
- Setting a job description inside the same thread that calls the action is always safe.
- Setting a job description in a thread that spawns other threads, which then call actions, is also safe.
- Setting a job description in a thread while the corresponding action is executed in an existing thread does not work. The job description that pre-exists for the latter thread is going to be used. This can be fixed by simply not reusing existing threads, but spawning new threads.
Conclusion
Job descriptions are very useful to add context to Spark queries, jobs and stages in the Spark UI. This helps to understand which parts of a Spark app, especially large ones, are misbehaving or underperforming.
The spark-extension package provides useful methods to set and restore job descriptions: appendJobDescription and withJobDescription.
Special care has to be taken when setting job descriptions in a multi-threaded Spark application. Job descriptions only propagate to new threads, never to existing threads.
Footnotes
[1]There are corner cases where multiple contexts are useful, but this has to be enabled explicitly. So this is not the default mode of operation.


