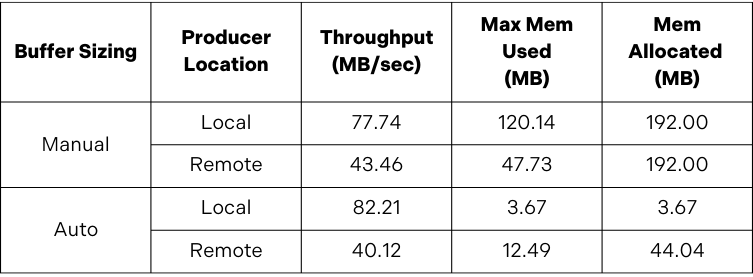
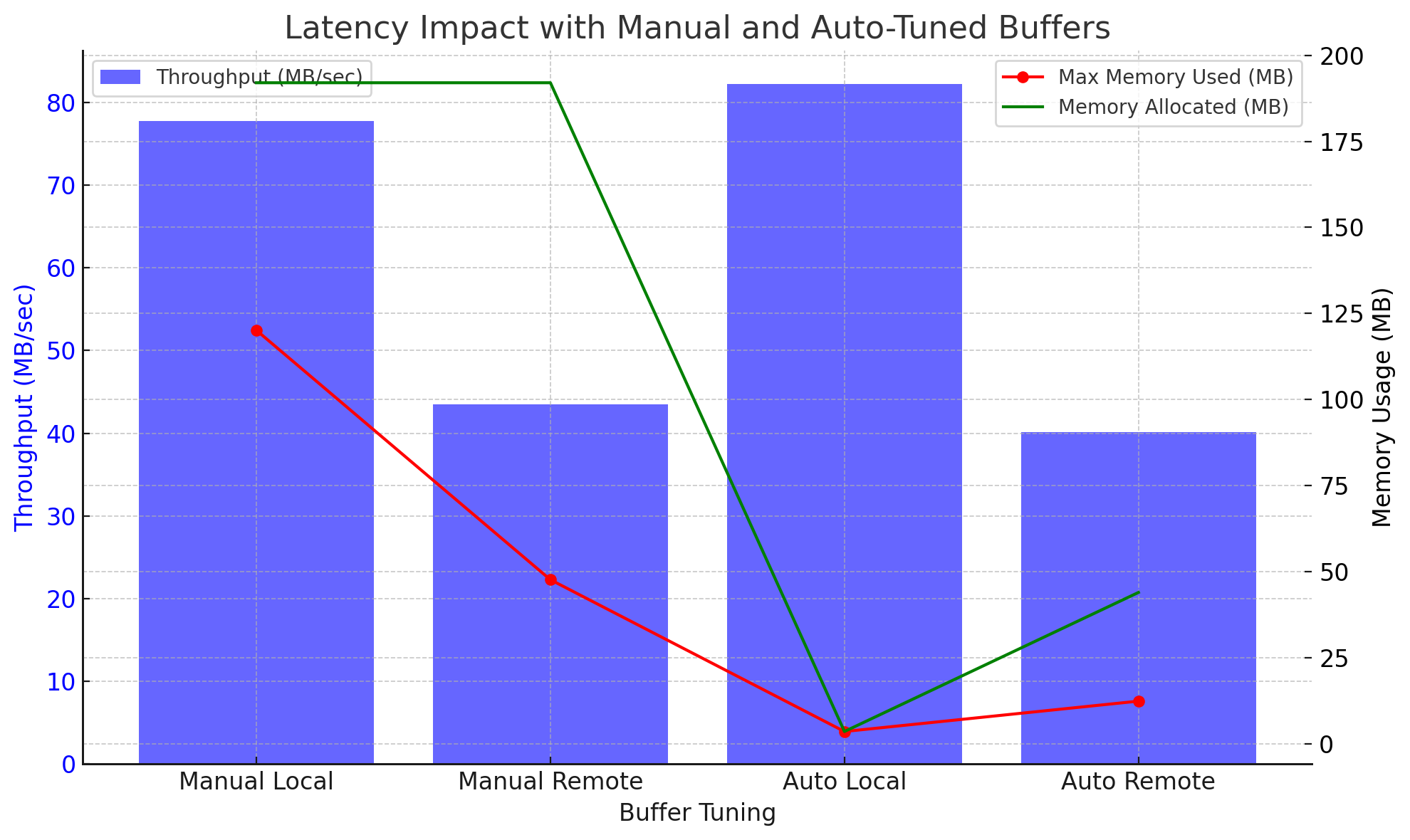
Baseline Testing
To answer this question, we needed a Kafka producer that could generate as many messages as quickly as possible. We would use this to establish the baseline throughput for our producer using a local Kafka cluster and then see what impact a high-latency network link has by running the producer in the remote data centre.
The application engineering team intended to use a librdkafka-based client, so it made sense for us to do the same. Like many Platform Engineering teams at G-Research, Python is our language of choice, and Python bindings are available for librdkafka.
The message throughput achieved with the first iteration of the producer was underwhelming, just a few megabytes per second. This was due to the cost of generating a fixed-length random string in Python. While it would have been interesting to benchmark different approaches and optimise them, it would have distracted us from our goal. To generate load, it was sufficient for every message to have an identical payload. With this change implemented, message throughput was much better at tens of megabytes per second.
Additionally, the first iteration used ThreadPoolExecutor to produce multiple messages in parallel. However, since the producer was CPU-bound, it didn’t benefit from Python threads as it could not fully utilise multiple CPU cores because the Global Interpreter Lock (GIL) means only one thread can execute Python code simultaneously. Using multiprocessing instead of ThreadPoolExecutor overcame this limitation, as each process has its own Python interpreter and memory space, bypassing the GIL entirely.
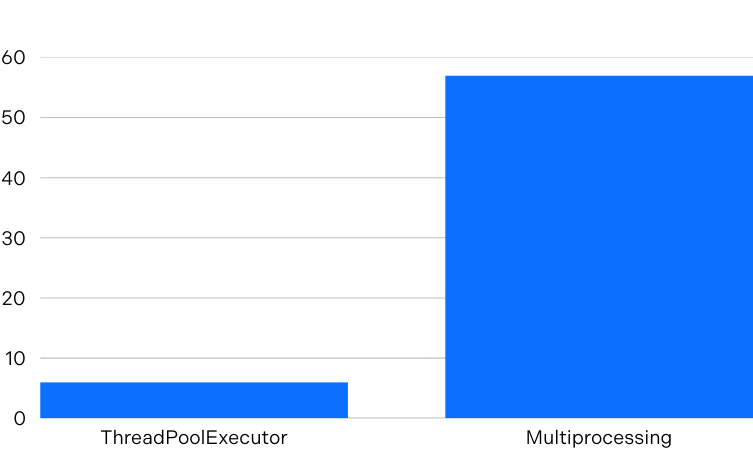
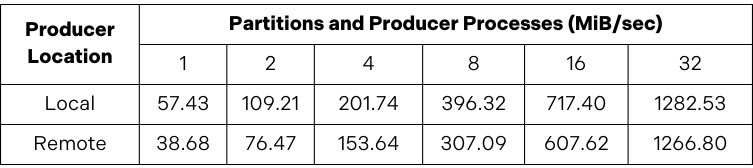
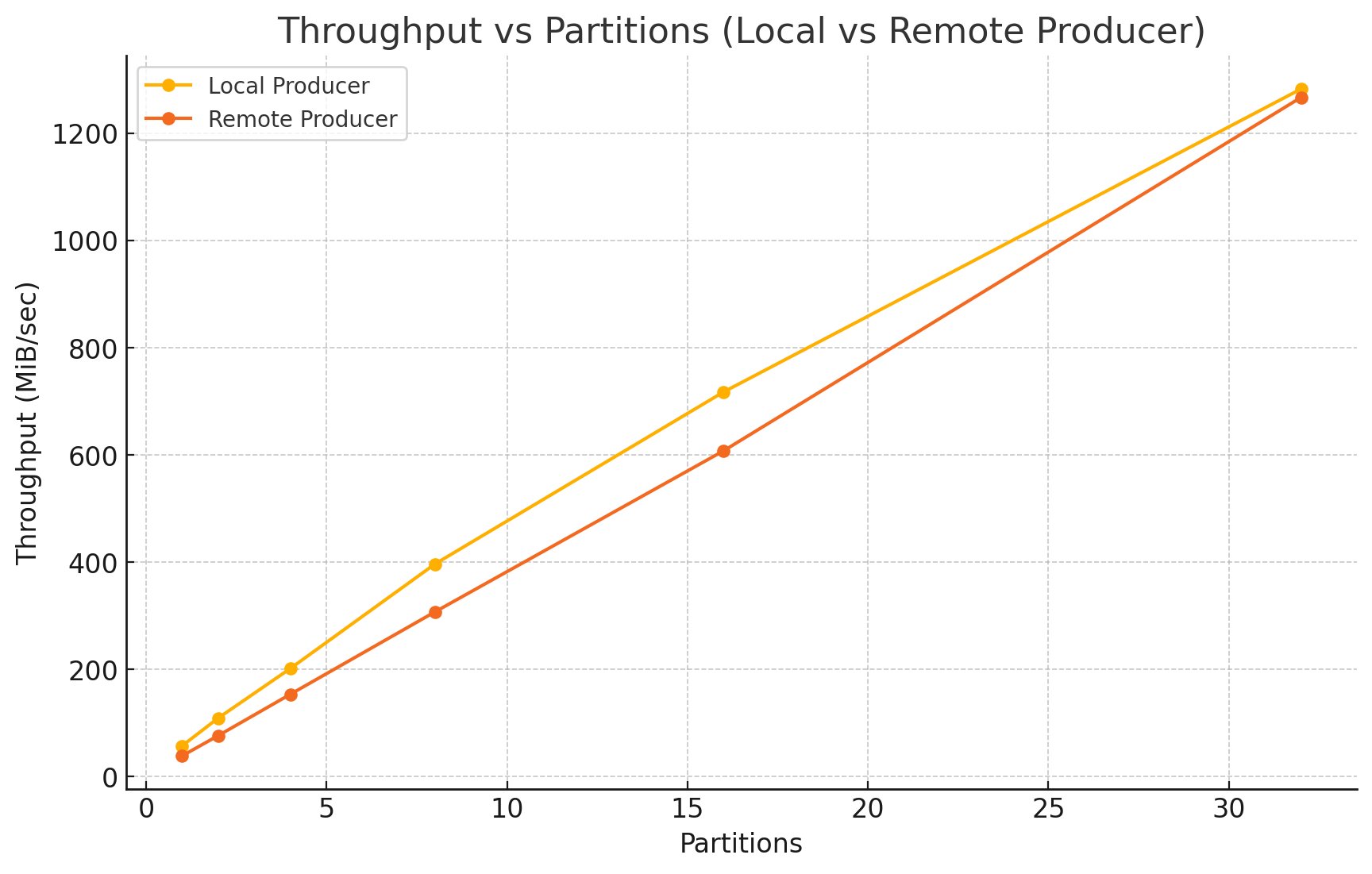
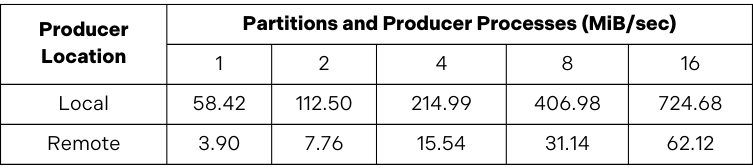
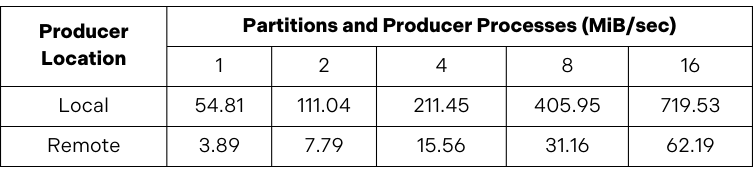
Having made these changes, a single process (with acks=all) could write 100-byte messages at 57 megabytes per second and continue to scale as additional processes and topic partitions were added. For example, with 32 processes and partitions, message throughput was 1.28 gigabytes per second.
Remember that these results do not measure the limits of what can be achieved with Apache Kafka. The goal was to generate sufficient load to meaningfully evaluate the impact of network latency on Kafka producer throughput by establishing a baseline for when the producer and Kafka cluster are located in the same data centre.
After establishing this baseline, we ran the producer in the remote data centre. When we did this, throughput plummeted to just 4 megabytes per second.