Philippe Formont, Maxime Darrin, Banafsheh Karimian, Jackie CK Cheung, Eric Granger, Ismail Ben Ayed, Mohammadhadi Shateri, Pablo Piantanida
The paper tackles the problem of distilling multiple large embedding models into a single, task-agnostic student representation. Existing multi-teacher knowledge distillation methods typically rely on task labels or task-specific heads and are tuned to a single downstream objective, which makes them hard to reuse on unseen tasks.
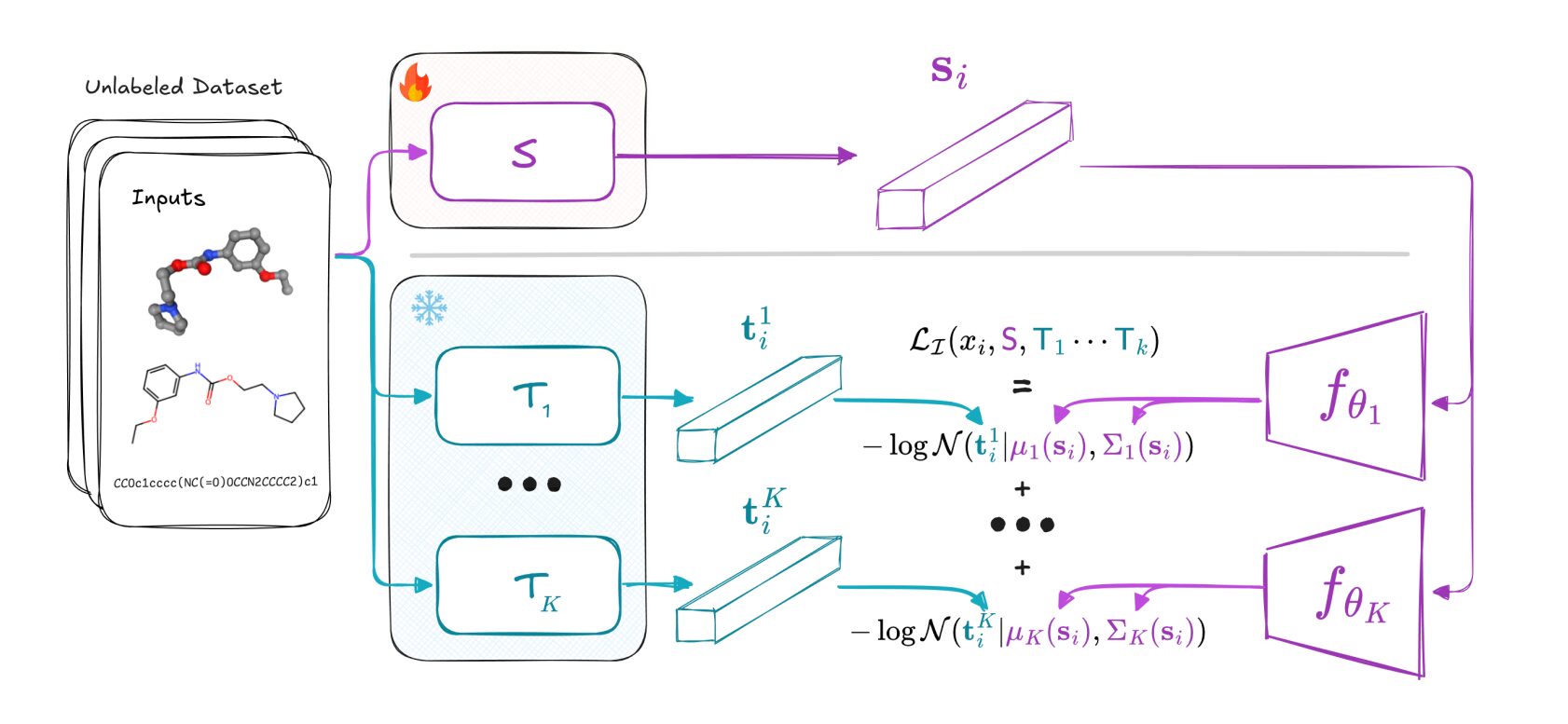
The authors instead define a “task-enabling” view of distillation, comparing the Bayes-optimal classifiers induced by teacher and student embeddings for arbitrary downstream tasks. They prove that the probability that the student’s Bayes classifier disagrees with the ensemble of teachers can be controlled via the conditional entropy of the teachers’ embeddings given the student embedding, leading to an information-theoretic loss that maximises mutual information between student and teachers.
Concretely, they implement this loss with a differentiable Gaussian mixture estimator of conditional entropy and train student embedders on unlabelled data from text, vision and molecular domains. After distillation, the student is frozen and simple feed-forward heads are trained for a variety of classification, regression, clustering and similarity benchmarks.
Across modalities, the distilled students achieve competitive and often improved performance compared to the best individual teachers and prior distillation baselines, while remaining compact and task-agnostic.
This paper is appealing because it shows how to compress the knowledge of many strong foundation models into a single, general-purpose representation without needing task labels.
As many people are currently focusing on creating better and better foundation models, this paper shows how people can fuse multiple different models into a single smaller one. This can be beneficial for academia and industry as it will allow saving hardware whilst improving the final model.
Learning Task-Agnostic Representations through Multi-Teacher Distillation