Solving hard threat-hunting problems with smart data structures + Rust
- Open-source software
Written by Ardavan Alamir, Lead Security Data Scientist and George Thomas, CSIRT Analyst
When you spot an Indicator of Compromise (IOC), searching, sorting and sifting through command line terms is typically so inefficient that it’s only done in post-mortem, rather than in real-time. And when you’re hunting threats, quicker is better.
We turned the challenge of running retrospective searches on historical data into something security teams can do in near real-time. Using a new smart data structure, alongside an advanced search algorithm, we’ve been able to rapidly accelerate our threat response time, reducing a common benchmark command line search time from nearly two weeks to less than five minutes.
We’re open sourcing this advanced new tool to help people protect themselves, with the hope that it will help increase the safety of us all.
The issues
One of the biggest challenges facing security teams when they respond to security incidents is running searches on historical data.
Deep into an incident, it may dawn on you that the activity you’re investigating began weeks or months ago. You may even have to go back through years of data to find when the compromise began, or to verify that you haven’t missed anything. If you’re collecting and storing the right logs, this helps drastically, but how do you search through them all?
The other issue that faces any Security Operations Centre is threat hunting. Sometimes, you might be made aware of a malware IOC that you weren’t looking for, leading you to want to run a historic search for any occurrences on your network.
Numerous malware use the Windows command shell to script commands and searching for these means searching for malicious commands in billions of often long and complex command line logs over several months.
These IOCs may be specific matches or loose ones, requiring regex-based searches to investigate. Again, how do you go through your data quickly enough for your searches to be of use? This was an issue which we routinely came across in the security team at G-Research; how do we process this data in Jupyter notebooks quickly enough to be of use?
You may have a rough idea of the command you’re looking for or you may be actively looking for specific commands run by malware you know was installed. Sometimes you may be looking for activity from opportunistic hackers who have already made it into your network and who are trying to operate from within — what is commonly called living off the land.
For example, the Command and Scripting Interpreter Mitre Technique was ranked as the top technique in the Red Canary 2021 Threat Detection Report, accounting for 24% of the total number of threats in the report. This is one of the kinds of attacks we looked for based on Threat Intelligence.
A lot of prominent malware variants abuse this technique. For example, if you suspect the Lazarus APT group have left some malware on your systems you may look for a command like:

This should be easy to detect. We have a lot of features we can look for such as “/haobao”, which will only have been entered by malware, but we still have to look for specific terms through billions of strings.
On the more difficult end of the spectrum, a big reason for the prevalence of Command and Scripting Interpreter attacks is that the attackers can live off the land. Whilst malware does do this to an extent, it still involves some level of installation on the target machine, even if it’s living in memory or running processes. But if an attacker has accessed a machine using valid credentials, they may never need to use any malware at all to achieve their goals.
The challenge
When attackers live off the land, it can be especially difficult to detect their presence as there are myriad commands an attacker could run using existing infrastructure, as well as many different ways they could run these commands. This means potentially running a highly detailed regex search across billions of command line fields, across weeks and possibly months of data.
If you don’t have the luxury of waiting a week for your results to come back – and realistically, who does? – how do you get your results back quickly enough for them to be of use to you during an incident, or to be useful for Threat Hunting?
At G-Research, we started to look at smarter ways of searching through logs using Jupyter Notebooks and Pandas.
Our starting point: Regexes and a benchmark
Regular Expression (Regex) is a naïve way to match a set of string patterns. The power of Regex lies in the expressiveness of its search patterns. For example, you can search for an IP subnet by writing 192.168.25.d{1,3}. In Python, using Regex to match multiple patterns over a single log event looks like:

We established an internal benchmark dataset where we tried to match some 10,000 patterns over 150 million command lines. The command line strings were extracted from the Window Eventlogs – Event ID 4688.
The Regex solution would take over 11 days on a single CPU core. This is impractical. One obvious solution is to parallelise the computation on multiple cores but to bring down the computation from days to minutes or less would require a lot of cores. For organisations that have deep pockets for their cybersecurity functions, that can be feasible. But such a task could incur expensive AWS bills if the command line searches need to be frequent.
In search of a better algo
Being interested in data structures, we wondered if there were any clever ones that could reduce the time complexity. At the end of the day, anyone grinding through Leetcode and HackerRank needs to add value to the business.
One data structure that we thought could be relevant is the Trie structure. This was introduced by Rene de la Briandais in 1959 and Edward Fredkin in 1960. It is a tree-like structure optimised for string searching. They are used in search engines to speed up the auto-completion suggestions as a user types their search.
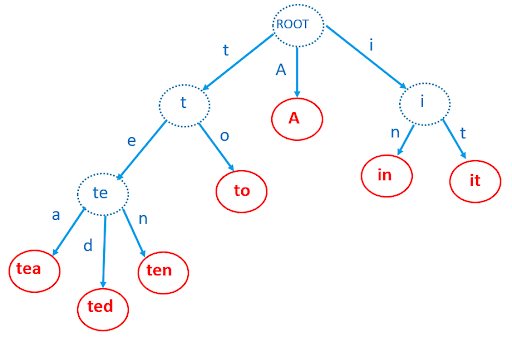
It is a tree whose edges are alphabet characters. Its nodes are prefixes of the searched patterns. Thus you form a child node by adding a character to the prefix node you have already traversed.
In that sense, it is a depth-first search (DFS) tree that can have between 0 and 26 children nodes per parent. Terminal nodes correspond to the full pattern words. As you type, the search space becomes massively reduced to those sharing the prefix you’ve already entered, which means there’s no longer a need for a linear time search over all pattern words.
The time complexities for a Trie search are:
- Pre-process time to build Trie over the patterns: O( Sum(length of Pattern strings) )
- Search time over a cmd line: O(Length cmd line * Length of longest pattern)
The initial trade-off to build a Trie structure significantly reduces subsequent search time, especially when repeated over millions of command lines.
Top tip: A good Python implementation of the Trie can be found at https://pytrie.readthedocs.io/
Using our internal benchmark set of 10,000 patterns over 150 million command lines, the time was shortened to under seven hours, from a Regex start point of 11 days.

Shortening computations from days to hours is an impressive time gain. However its benefit remains when performed offline. When a security analyst is responding to an incident, waiting seven hours is not an option. Could we trim off more time complexity with another clever trick?
The search continues
We enlisted the help of the G-Research Open-Source team and worked with Itamar Turner-Trauring, a seasoned Python open-source contributor.
Itamar suggested the use of an improved Trie structure called the Aho-Corasick algorithm, proposed by Alfred Aho and Margaret Corasick in 1975. Its improvement lies in the addition of links between nodes that share common suffixes so that, after a failed search, there is no need to backtrack all the way up to the root node and traverse down again. It is what you call in computer science a finite state machine.
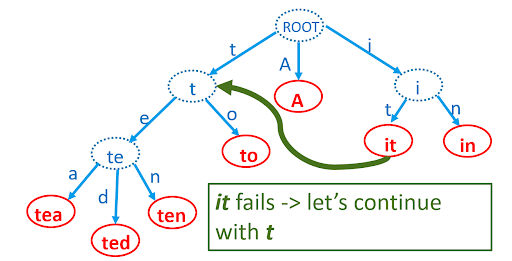
The time complexities for an Aho-Corasick search are:
- Pre-process time to build tree over the patterns: O( Sum(length of Pattern strings) )
- Search time over a cmd line: O(Length cmd line + Number of matched patterns)
The Aho-Corasick search time is faster than the Trie’s when matching patterns over a long command line.
Solutions outside Python
Another axis of the research was looking at non-Pythonic solutions. Python, being a high-level dynamically typed, interpreted language, is notoriously slow. The overhead comes from the fact that Python instructions are interpreted and compiled during runtime. If you need to speed up, you need to look at alternatives.
For example, fast number crunching can be done with the NumPy library which translates Python objects into C code. Unfortunately, no such solution exists for string processing. Numba and Cython were tried, but in the end, Rust was deemed the best solution.
Top tip: For more details on the research, see Cython, Rust, and more: choosing a language for Python extensions by Itamar.
The inevitable Rust detour
Rust is the new kid on the block when it comes to systems-level programming languages. It is known to be as fast as C++ while having the memory safety that C++ famously lacks.
In the words of Elias Gabriel Amaral da Silva, a contributor to the Rust Users Group: “Rust is a language that, because it has no runtime, can be used to integrate with any runtime; you can write a native extension in Rust that is called by a program node.js, or by a Python program.”[1]
Rust has a good library for binding with Python called PyO3. The core of PyO3 is maturin which builds the Rust crates for Python.
The way it works is that first you need to write the function/class that requires some speed-up in a separate file with the Rust syntax. You then declare that function/class in a configuration cargo.toml file with the naming it will have as a Python module. Finally, you compile it with the Rust compiler cargo. You can then import your Rust compiled function in your Python project like any other module.
Top tip: A good Rust implementation of the Aho-Corasick library exists and we wrote a Python wrapper around it to use in our threat-hunting notebooks.
Finally…back to security
We needed a solution that would deliver its results back to the Jupyter Notebook ecosystem that our security analysts use, which explains why we didn’t just use Rust. We place a high value on interoperability and this solution delivers it.
Testing the Aho-Corasick solution on our internal benchmark of 10,000 patterns of over 150 million command lines, the time got reduced to a tiny four minutes!

Let’s recall our comparisons:
- Regex: 11 days
- Trie: 7 hours
- Aho-Corasick + Rust: 4 mins
This is a huge improvement. Suddenly we’ve turned the daunting and time-sapping prospect of searching for terms in the command line to something that’s useful during a Threat Hunt instead of just a post-mortem.
We’ve equipped the security team with the tools it needs to both rapidly respond and combat bad actors in near real-time. The results we were able to achieve collaborating between CSIRT, Security Data Engineering and Open Source teams were remarkable.
G-Research has decided to share the library with the entire open-source community: https://pypi.org/project/ahocorasick-rs/.
We hope it will be a welcome addition to the toolkit of security analysts and detection engineers.
[1] https://developers.redhat.com/blog/2017/11/16/speed-python-using-rust#what_is_rust_